When developing a Spring Boot application with Spring Data JPA, ensuring that database table and column names are consistent and meaningful is crucial for maintainability and readability. This is where naming strategies come into play. In this blog, we will dive into the physical naming strategy, exploring its purpose, specific use cases, and the distinct advantages it offers to developers. By understanding and implementing this strategy, you can achieve greater control over your database schema, leading to a more robust and manageable application.
Prerequisites
Before reading this blog on the physical naming strategy, it is recommended that you must possess a basic understanding of how Spring Boot works and how it communicates with the database.
Quick Recap of Basic Concepts
Before diving into the main topic, let’s quickly recap the definitions of JPA, Hibernate, and Spring Data JPA.
Java Persistence API (JPA)
Java Persistence API, or JPA, provides a specification for persisting, reading, and managing data from Java objects to relational tables in the database.
Hibernate
Hibernate provides a reference implementation of JPA. It is an Object Relational Mapping (ORM) solution for Java projects. ORM is the programming technique used to map application entity model objects to relational database tables.
Spring Data JPA
Spring Data JPA is a part of the Spring Framework. The goal of this framework is to significantly reduce the amount of boilerplate code required to implement data access layers for various persistence stores. Spring Data JPA is not a JPA provider, It adds an extra layer of abstraction on top of Hibernate or any other JPA provider, such as EclipseLink.
Now that we’ve refreshed our understanding of these basic concepts, let’s explore the physical naming strategy in detail.
What Physical Naming Strategy Means
In Spring Boot, a physical naming strategy controls how table and column names are mapped to the names defined in Java entities. Unlike the implicit naming strategy, which derives names based on conventions and mappings, the physical naming strategy allows us to directly influence the exact names used in the database. For example, if there is an entity class named User, its logical name will be User, but by using a physical naming strategy, we can convert logical names to physical names (i.e., the actual names in the database).
Purpose of Physical Naming Strategy
The main purpose of the physical naming strategy is to give developers more control over the database. By defining a physical naming strategy, you can ensure that the table and column names in your database match exactly what you expect, regardless of the naming conventions used in your code.
Use Cases for Physical Naming Strategy
Consistency with Existing Databases:
If you’re integrating with an existing database that has a predefined naming convention, using a physical naming strategy ensures your entity names match the database exactly.
Migration and Legacy Systems:
When migrating from a legacy system to Spring Boot, the physical naming strategy helps maintain the original database details, avoiding the need for extensive database modifications.
Efficient Management of Multiple Database Schemas:
If your application needs to communicate with multiple databases or switch databases based on different environments, using a physical naming strategy allows you to manage all these configurations from a single Java class. This centralization simplifies the management of multiple databases and ensures consistency across different environments.
Compliance with Company Standards:
Some organizations have strict naming conventions for databases. A physical naming strategy allows you to enforce these conventions consistently across all your database tables and columns.
How Physical Naming Strategy Works
A naming strategy is a set of rules that Hibernate uses to convert logical names to physical names. The PhysicalNamingStrategy interface allows us to customize these rules.
During the initial startup or schema generation phase, Hibernate processes entity metadata (values defined in @Table, @Column annotations, etc.) and applies the naming strategy to them. The result after this processing is the physical names of tables and columns, which Hibernate caches in its internal metadata structures. For subsequent operations, Hibernate reuses the cached physical names rather than recalculating them. For example, you have an entity User. Here’s the flow:
- Startup: Hibernate initializes and processes the User entity. It calls methods from the implementations of the physical naming strategy to convert User to the physical names, and caches the result.
- SQL Operations: For a SELECT query, Hibernate uses the cached physical name of the User entity without calling the methods of the physical naming strategy again. This applies to all SQL operations (e.g., INSERT, UPDATE, DELETE) involving the User entity.
Implement Physical Naming Strategy in Spring Boot
Suppose you have two environments, PROD and SIT, for your application. For the PROD environment, the application needs to connect to two databases – myAppDB and alphaAppDB. For the SIT environment, the application needs to connect to sitDB. Each PROD database contains one table: myAppDB has MY_APP_USER, alphaAppDB has ALPHA_APP_USER, and the SIT database, sitDB contains both MY_APP_USER and ALPHA_APP_USER.
Here, for the PROD environment, myAppDB is the default database, (i.e db config defined in the properties file) and for the SIT environment sitDB is the default database.
Now, your database team configures database tables in a way where all table names and their column names are in uppercase letters. So, as a developer by using a physical naming strategy, you can manage all these configurations and ensure consistent naming conventions across different databases and environments.
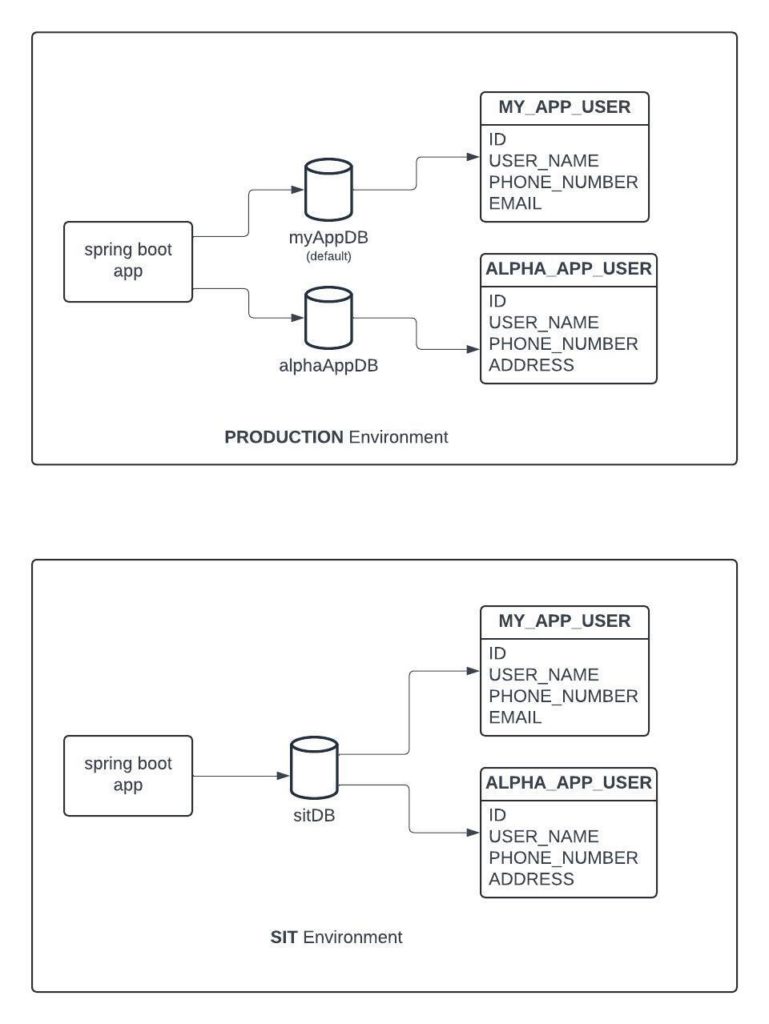
The scenario described above, there are two challenges for a developer and here we can use the physical naming strategy to overcome these challenges.
Challenge One: Uppercase table and column name
Let’s assume the database team configures the database tables such that all table names and column names are in uppercase letters. Since Hibernate generates the names of the tables and their columns in lowercase letters by default, querying data in these tables via your Spring Boot app will result in an exception. You will see the following message in the application console:
2024-05-24T18:12:59.009+06:00 WARN 51029 --- [my-app] [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1146, SQLState: 42S02
2024-05-24T18:12:59.010+06:00 ERROR 51029 --- [my-app] [ main] o.h.engine.jdbc.spi.SqlExceptionHelper : Table 'myAppDB.my_app_user' doesn't exist
In this error message, the last line indicates that a table named my_app_user in the myAppDB database doesn’t exist. This is true because, in the myAppDB database, the name of the table is in uppercase letters: MY_APP_USER.
So, how can this be solved? When creating entities in the application, you need to explicitly specify the table name using the @Table annotation and the column names using the @Column annotations. Example,
@Data
@Entity
@Table(name = "MY_APP_USER")
public class MyAppUser {
@Id
@Column(name = "ID")
private Long id;
@Column(name = "USER_NAME")
private String userName;
@Column(name = "PHONE_NUMBER")
private String phoneNumber;
@Column(name = "EMAIL")
private String email;
}
However, your application still does not follow your instruction by default. To ensure that your Spring Boot app uses the values specified in the annotations in the entity class, you need to configure it in the properties file, by telling it that it must use a physical naming strategy, like this:
spring.jpa.hibernate.naming.physical-strategy = org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
There are two implementations of the PhysicalNamingStrategy interface already provided with Spring Data JPA. One is PhysicalNamingStrategyStandardImpl, which will use the values passed in the @Table annotation and @Column annotation as the table name and column name, respectively. The other one is CamelCaseToUnderscoresNamingStrategy (you can infer its functionality from its name, but feel free to explore it further!!).
Challenge Two: Managing Multi-Database Communication
In our hypothetical scenario, the Spring Boot app needs to maintain multiple databases to query data in the PROD environment. You can easily manage this environment-specific multi-database connectivity by defining your own physical naming strategy and overriding the default implementations.
@Configuration
@RequiredArgsConstructor
public class MyAppPhysicalNamingStrategy implements PhysicalNamingStrategy {
private final Environment env;
private final List<String> alphaAppTables = Arrays.asList("ALPHA_APP_USER");
@Override
public Identifier toPhysicalCatalogName(Identifier identifier, JdbcEnvironment jdbcEnvironment) {
return identifier;
}
@Override
public Identifier toPhysicalSchemaName(Identifier identifier, JdbcEnvironment jdbcEnvironment) {
return identifier;
}
@Override
public Identifier toPhysicalTableName(Identifier identifier, JdbcEnvironment jdbcEnvironment) {
AppEnvironment currentEnv = CommonUtils.getCurrentEnv(env);
String databaseType = DatabaseType.fromEnvironment(currentEnv, identifier.getText(), alphaAppTables);
return new Identifier(databaseType + "." + identifier.getText(), identifier.isQuoted());
}
@Override
public Identifier toPhysicalSequenceName(Identifier identifier, JdbcEnvironment jdbcEnvironment) {
return identifier;
}
@Override
public Identifier toPhysicalColumnName(Identifier identifier, JdbcEnvironment jdbcEnvironment) {
return identifier;
}
}
Here, a custom physical naming strategy is defined to override the existing implementations. To overcome the challenge, we need to work on the toPhysicalTableName method. As we know, Hibernate generates the table name with the database name separated by a dot, like this: databaseName.TableName. To achieve this, we need to define a new identifier where we pass our database name based on the active profile and the table name. This way, Hibernate can generate the table name as expected.
Below is the code snippet of DatabaseType enum:
@Getter
@RequiredArgsConstructor
public enum DatabaseType {
PROD_MY_APP_DATABASE("myAppDB"),
PROD_ALPHA_APP_DATABASE("alphaAppDB"),
SIT_DATABASE("sitDB");
private final String name;
public static String fromEnvironment(AppEnvironment env, String tableName, List<String> alphaAppTables) {
if (AppEnvironment.PROD.equals(env)) {
if (alphaAppTables.contains(tableName)) {
return PROD_ALPHA_APP_DATABASE.name;
} else {
return PROD_MY_APP_DATABASE.name;
}
}
return SIT_DATABASE.name;
}
}
The DatabaseType enum plays a vital role in deciding which type of database to choose. Here, database type refers to either the PROD database or the SIT database. The fromEnvironment method helps determine the appropriate database type based on the active environment and the table the application needs to connect to.
By employing a physical naming strategy, we overcome the challenge of uppercase table and column names as well as the management of multiple databases based on different environments.
Benefits for Developers
Reduced Errors
When your Java entities match the database schema exactly, it reduces the likelihood of errors due to mismatched names. This ensures smoother operations, especially when working with complex queries and data migrations.
Improved Readability
Consistent naming makes your code and database schema easier to read and understand. This is particularly beneficial in a team environment where multiple developers interact with the database.
Simplified Maintenance
When table and column names are predictable and consistent, maintaining and updating the database schema becomes simpler. This consistency aids in debugging and enhances overall productivity.
Source Code
You can find full details about the application and explore the codebase through this link:
https://github.com/mukitul/hibernate-naming-strategy-in-spring-boot
Conclusion
The physical naming strategy in Spring Boot is a powerful tool for developers, providing precise control over database names. By ensuring consistency, reducing errors, and simplifying maintenance, this strategy can significantly enhance the development experience. Implementing a custom physical naming strategy is straightforward and can be tailored to meet specific project requirements, making it an essential practice for managing database schemas effectively in Spring Boot applications.
The End!