In today’s digital era, information is just a search away. Whether we are looking for the latest news, a nearby restaurant, or a technical solution, most of us instinctively turn to Google. But have you ever wondered what happens behind the scenes when you type a query into the search box and receive millions of results in less than a second?
Google Search is more than just a website — it’s one of the most advanced systems ever built to organise and deliver the world’s information. Understanding how it works is not only fascinating but also valuable for businesses, developers, and everyday users. In this article, we’ll take a closer look at the journey of Google Search from its early beginnings to the sophisticated algorithms that power it today.
The Problem: RetryiBefore Google: How Early Search Engines Workedng Too Fast
In the early days of the internet, search engines looked very different from what we know today. Platforms like AltaVista, Lycos, and Yahoo Directory tried to make sense of a rapidly growing web, but their methods were fairly basic.
Most early search engines relied on keyword matching. They scanned web pages for specific words in titles, meta tags, or content, and then listed results that contained those words. While this worked to some extent, it had serious flaws:
- Irrelevant results: A page might contain the right keywords but have nothing to do with what the user actually wanted.
- Easy to manipulate: Website owners quickly learned they could “game” the system by stuffing pages with repeated keywords, even if the content wasn’t useful.
- No concept of authority: All pages were treated equally, so a random personal blog could outrank a credible research paper if it used the right keywords.
- Limited scalability: As the web grew, these simple approaches couldn’t keep up with billions of pages being added.
The result was often a frustrating experience, as users had to sift through multiple irrelevant results before finding something beneficial.
The Rise of Google: From a Student Project to a Search Revolution
This problem caught the attention of two Stanford PhD students, Larry Page and Sergey Brin. In 1996, they initiated a research project called Backrub, aiming to develop a more reliable method for evaluating web pages.
Instead of just counting keywords, they looked at how websites were connected through links. Their reasoning was simple but powerful: if one page linked to another, that link could be seen as a “vote of trust.”
This insight led to the creation of the PageRank algorithm, a groundbreaking method that measured not only the presence of information but also its credibility. Pages with more high-quality links naturally ranked higher, making results more relevant and trustworthy.
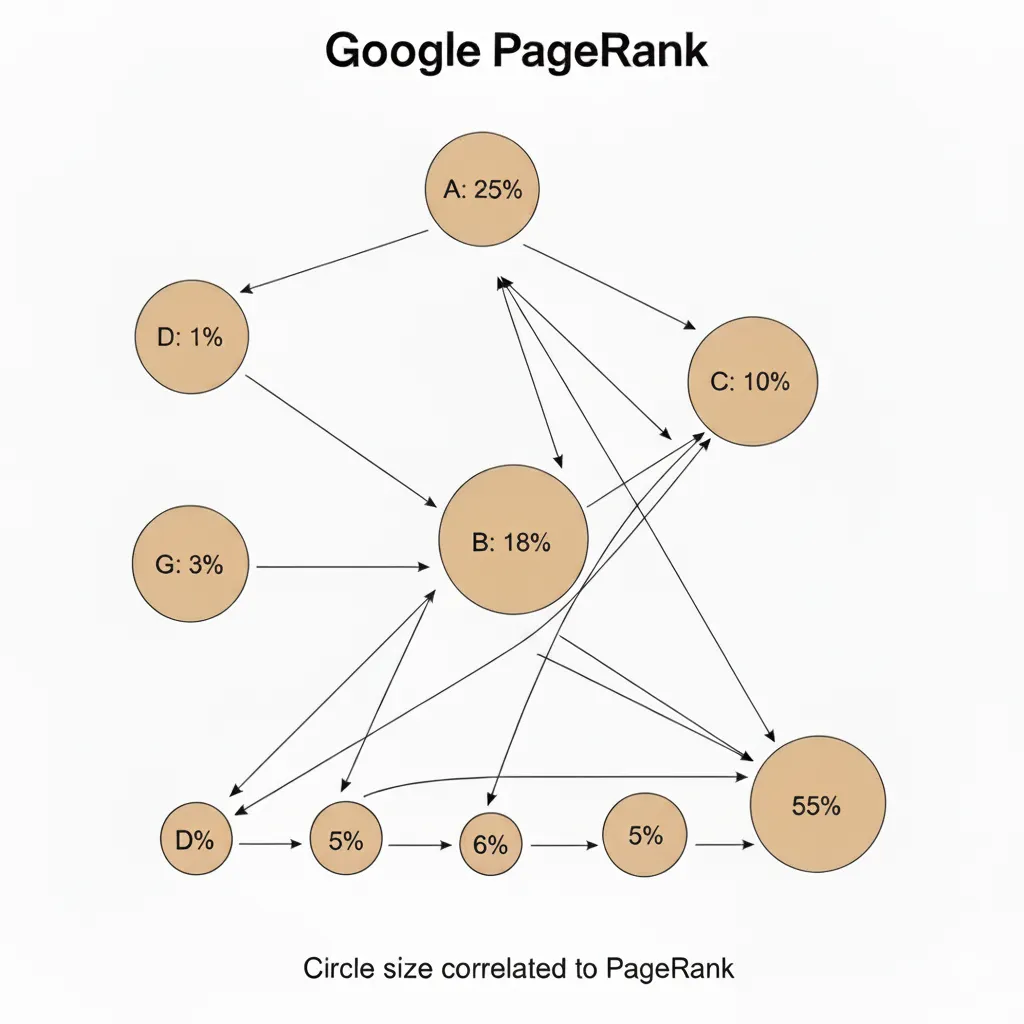
By 1998, Page and Brin registered the domain google.com, a name inspired by the mathematical term “googol” (a 1 followed by 100 zeros). What began as a university project soon evolved into the world’s most powerful search engine, establishing a new standard for accuracy and efficiency in online search.
How Google Search Works
At a high level, Google Search operates through a continuous cycle of discovering, organizing, and ranking information. When you enter a query, Google doesn’t search the entire web in real time — instead, it relies on an enormous pre-built index of web pages.
Summary of three main stages:
- Crawling: Google’s automated bots explore the web, following links to discover new and updated content.
- Indexing: Discovered pages are analysed, categorized, and stored in Google’s index, making them quickly searchable.
- Serving & Ranking: When a user searches, Google retrieves relevant pages from the index and ranks them using hundreds of factors, delivering the most useful and authoritative results.
Press enter or click to view image in full size
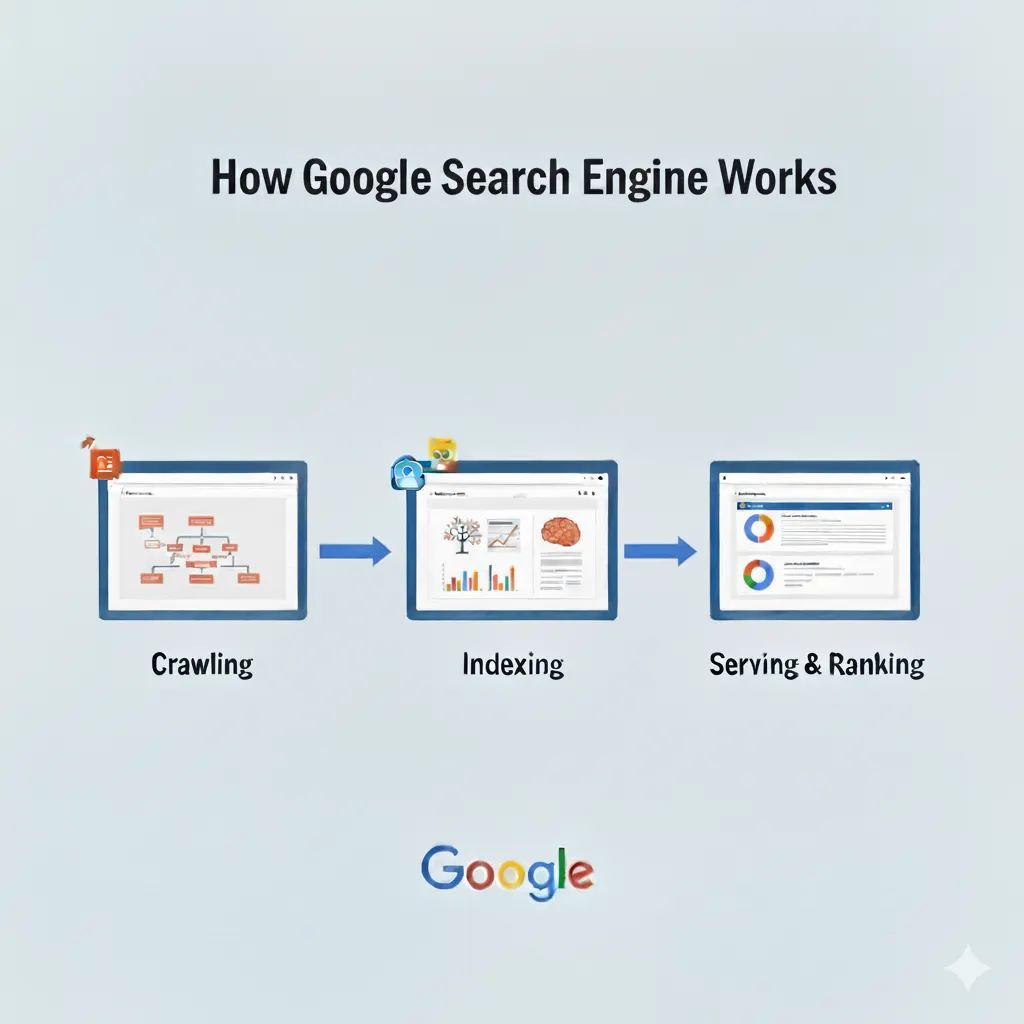
This high-level flow ensures that search is both fast and relevant, even as the web continues to grow at an extraordinary pace.
Step 1: Crawling — Discovering the Web
Crawling is the first step in Google’s search process. It involves automated programs called Googlebots (or web crawlers) that continuously explore the internet to discover new and updated web pages. These bots follow links from one page to another, creating a constantly expanding map of the web. Google can also discover pages through sitemaps submitted by site owners.
The goal of crawling is simple: find content that could be relevant to users’ queries. Googlebots priorities which sites and pages to visit based on factors like site structure, update frequency, and link popularity. Well-structured websites with clear navigation and internal linking are easier for bots to crawl, which helps ensure that all important pages are discovered.
Step 2: Indexing — Organising the Information
Once Googlebot discovers a page, the next step is indexing, storing and organizing the information so it can be quickly retrieved when users search. Think of it like a librarian not only noting that a book exists, but also cataloguing its contents so it can be easily found later.
During indexing, Google analyses the page’s content in detail, including:
- Text: main content, headings, and keywords
- Media: images, videos, and alt text
- Metadata: title tags, meta descriptions, structured data
- Page quality signals: freshness, relevance, and mobile usability
A crucial part of indexing is identifying canonical pages. Google groups together pages with similar or duplicate content (a process called clustering) and selects the most representative page as the canonical version. This is typically the page shown in search results, while other pages in the cluster may appear in specific contexts, like mobile searches or very targeted queries.
Google also collects additional signals about the canonical page, such as language, geographic relevance, and usability, which influence how the page is served in search results. During this process, Google renders the page as a modern browser would, executing JavaScript to capture dynamic content. Pages that are blocked from crawling, inaccessible, or fail to load properly are usually excluded from the index.
All indexed information is stored in Google’s massive search index, a highly optimized database hosted across thousands of computers.
Step 3: Serving & Ranking — Delivering the Best Results
After crawling and indexing, the final step is serving search results, the process of matching a user’s query with the most relevant pages from Google’s index. When someone types a keyword or question into the search bar, Google’s systems don’t scan the live web in real time. Instead, they search the pre-built index, which is optimized for speed and accuracy.
But serving is not just about retrieving pages. It’s about ranking them. Out of billions of possible matches, Google must decide which results are the most useful. This is where complex algorithms and ranking signals come into play.
Some of the major factors influencing ranking include:
- Relevance: How closely the page content matches the user’s query.
- Quality of content: Expertise, trustworthiness, depth, and originality of the information.
- Usability: Mobile-friendliness, page speed, and overall user experience.
- Freshness: How recently the page was updated, especially for time-sensitive queries.
- Context & personalisation: The user’s location, language, device, and past search behavior.
Once the ranking process is complete, Google serves results in the familiar Search Engine Results Page (SERP). Beyond the traditional “blue links,” SERPs now often include rich results such as featured snippets, images, videos, knowledge panels, or local map listings, depending on what best answers the query.
In essence, serving and ranking ensure that when you search, you don’t just get results, you get the best possible results, tailored to your intent and context.
Conclusion
Google Search may feel like magic when results appear in less than a second, but behind the scenes, it’s a carefully engineered process. From crawling the web to discover new content, to indexing and organizing information, and finally serving and ranking results using hundreds of signals, each step is designed to ensure users get the most relevant and reliable answers possible.
For businesses and developers, understanding this process is more than just interesting — it’s practical. Knowing how search works can guide better decisions in website design, content creation, and optimization strategies. For everyday users, it’s a reminder of the incredible scale of technology working silently in the background every time we type a query.
As Google continues to evolve with AI-powered search and generative results, understanding these fundamentals will remain essential for developers, businesses, and everyday users alike.
Google Search continues to evolve with AI. In our next blog, we’ll explore how machine learning shapes search today.