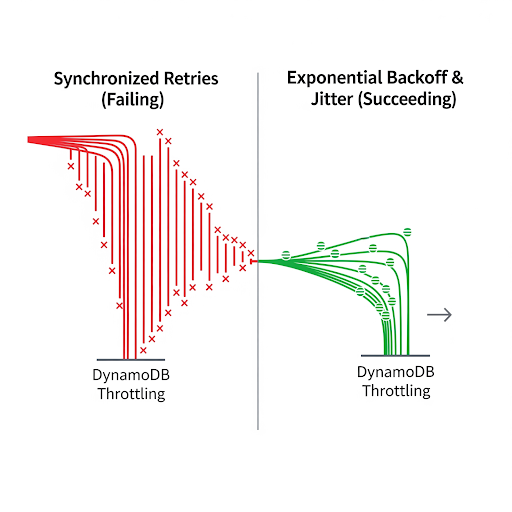
When working with DynamoDB, everything feels blazing fast—until you suddenly hit throttling. I learned this the hard way. Some of my write requests started failing, and when I retried them instantly, the results were almost identical: failures again.
Why? Because the database was throttling, and my retry strategy was making things worse, not better.
That’s when I discovered Exponential Backoff with Jitter, a retry pattern that not only improved my success rate but is also the exact approach AWS recommends.
Let’s break it down.
The Problem: Retrying Too Fast
Imagine you’re saving thousands of items to DynamoDB. If the provisioned capacity or adaptive capacity can’t keep up, DynamoDB starts rejecting requests with a throttling exception.
My first instinct? Retry immediately.
But here’s the catch: if you retry instantly, you’re hammering the database with the exact same load during its recovery window. No wonder the failures kept repeating.
Traditional Exponential Backoff
The most common retry strategy is Exponential Backoff.
Instead of retrying instantly, you increase the wait time after each failure:
- 1st retry → wait 50ms
- 2nd retry → wait 100ms
- 3rd retry → wait 200ms
- 4th retry → wait 400ms
And so on.
This helps a lot because it gives DynamoDB breathing space. But there’s still a problem: if multiple clients or threads are retrying in parallel, they all retry on the same schedule. This can create a retry storm, where everyone retries at the same time, overwhelming the system again.
Code: Traditional Exponential Backoff (Java)
public void saveItemWithExponentialBackoff(String item)
throws InterruptedException {
int maxRetries = 3;
long baseDelay = 50; // ms
for (int attempt = 1; attempt <= maxRetries; attempt++) {
try {
writeToDynamoDBSync(item);
System.out.println("Saved: " + item);
return;
} catch (ProvisionedThroughputExceededException e) {
long delay = (long) (baseDelay * Math.pow(2, attempt)); // 50ms, 100ms, 200ms
System.out.println("Retrying in " + delay + " ms");
Thread.sleep(delay);
}
}
}
private void writeToDynamoDBSync(String item) {
// Simulating random throttling
if (ThreadLocalRandom.current().nextInt(10) < 3) {
throw new ProvisionedThroughputExceededException("Throttled!");
}
}
This works better than retrying instantly, but as you can see, retries are predictable and synchronized.
Enter Jitter
This is where Jitter comes in.
Jitter means adding randomness to your backoff time. For example, instead of always waiting exactly 200ms before retrying 3 times, you wait anywhere between 0 and 200ms.
So instead of all clients retrying in lockstep, they spread their retries randomly across the time window. This avoids retry storms and smooths out the load.
Here’s a quick comparison:
Without Jitter (Exponential Backoff Only):
- Retries happen at fixed intervals (50ms, 100ms, 200ms…).
- Multiple clients hit the database at the same time.
- Throttling persists.
With Jitter (Exponential Backoff + Randomness):
- Retries happen within a random window (0–50ms, 0–100ms, 0–200ms…).
- Clients spread out their requests naturally.
The database has a better chance to recover.
Code: Exponential Backoff with Jitter (Java)
public void saveItemWithBackoffAndJitter(String item)
throws InterruptedException {
int maxRetries = 3;
long baseDelay = 50; // ms
for (int attempt = 1; attempt <= maxRetries; attempt++) {
try {
writeToDynamoDBSync(item);
System.out.println("Saved: " + item);
return;
} catch (ProvisionedThroughputExceededException e) {
long delay = (long) (baseDelay * Math.pow(2, attempt)); // exponential delay
long jitter = ThreadLocalRandom.current().nextLong(0, delay); // add randomness
System.out.println("Retrying in " + jitter + " ms");
Thread.sleep(jitter);
}
}
}
private void writeToDynamoDBSync(String item) {
// Simulating random throttling
if (ThreadLocalRandom.current().nextInt(10) < 3) {
throw new ProvisionedThroughputExceededException("Throttled!");
}
}
Notice how instead of waiting a fixed 200ms, the retry could happen anywhere between 0–200ms. That tiny difference prevents synchronized retries across multiple clients and gives DynamoDB room to breathe.
Why AWS Recommends It
AWS explicitly recommends Exponential Backoff with Jitter for DynamoDB, S3, and most of their APIs.
The reasoning is simple:
- DynamoDB is a shared resource.
- If every client retries in sync, throttling gets worse.
- Randomized retries prevent herd behavior and smooth traffic.
In my case, I retried each failed request at most three times with exponential backoff + jitter. That was enough to get nearly all the failed writes through successfully.
Takeaway
When working with DynamoDB (or any AWS service, really), don’t just retry instantly.
- Exponential Backoff prevents overwhelming the system with immediate retries.
- Jitter prevents synchronized retry storms.
- Together, they massively increase your chances of success.
For me, this small change was the difference between persistent failures and smooth recovery.