The goal of this article is to cover the internals of the Java Collection Framework to some extent as well as to provide some practical tips and techniques.
Understanding the internal mechanism of the Java Collection Framework will help you to write more efficient, cleaner, and reusable codes, as well as to avoid common pitfalls.
Background
Let’s assume we will create an e-commerce application holding hundreds of products and users. We must, therefore, keep them in a database. Let’s imagine a user searches for a specific product. There is a chance that there will be many more brands for that particular product. Furthermore, after retrieving them from the database, we want to sort them into different orders based on the user’s preference. So, where do you store them in the application’s backend before sorting? We will store our applications in an array if we wish to write them in C. Do we know the number of products (from different brands) in advance because it’s important to initialize the array with a specific size? So what’s the solution? Here are some possible solutions:
- Create a more extensive array, copy the elements from the original to the new one, and then delete the original array.
- Create a vast array from the beginning to accommodate any number of products, which may lead to memory wastage in most cases.
Although the first solution appears satisfactory, we must build and test this code, which will require more development time and testing scope. Furthermore, we must carefully ensure that there are no memory leaks, performance issues, or concurrency issues. Maintenance, reusability, and other factors must be considered in addition to modularity. These will undoubtedly compromise our delivery deadline.
In summary, what we initially thought was a trivial job became a terrific headache. If we go back to our initial requirement, we will find this differed from our goal.
Considering the above cases and scenarios, Java included abstract data types like List, Set, Queue, Map, etc. Their implementation classes with some practical algorithms to manipulate the data stored in the above data types in its core library so that developers do not need to think about those things independently. They can focus only on their business requirements.
Java Collection Framework
Now the question is– What’s the Java Collection Framework?
To answer the above question, first of all we need to know—what a collection is? And what is a framework?
A collection is a container that holds a group of objects.
A framework is a ready-made structure that simplifies the process of building something by providing a foundation, so you don’t have to start from scratch.
The Java Collection Framework is one of the fundamental aspects of Java programming that provides a unified architecture or structure to represent and manipulate collections of objects. In other words, it’s a set of interfaces and classes that implement commonly used data structures and algorithms to manipulate collections of objects.
Benefits of Java Collection Framework
Here are some key advantages of Java Collection Framework:
- Standardization: Standardization of common data structure simplifies code development and maintenance.
- Reusability: By using the framework’s pre-built classes and interfaces, you can avoid reinventing the wheel.
- Flexibility: The framework provides multiple implementations of the same data structure (e.g., ArrayList, LinkedList, HashSet, TreeSet). Therefore, you can easily switch between the implementations.
- Performance Optimization: Many of the classes in the framework are optimized for specific use cases. For example, ArrayList provides fast random access, while LinkedList offers efficient insertion and deletion. The choice of implementation can have a significant impact on performance.
- Interoperability: Collections in the framework adhere to a common set of interfaces (such as Collection, List, Set, Map), making it easier to interchange different types of collections. This consistency helps in writing generic code that can work with any collection type.
- Thread-Safety: For multi-threaded applications, the framework provides thread-safe implementations (e.g., ConcurrentHashMap) that can be used to avoid concurrency issues without needing to implement synchronization manually.
- Ease of Use: High-level abstractions make it easier to use and understand complex data structures.
- Maintained and Evolving: As a part of the Java Standard Library, the Collections Framework is well-documented, regularly updated, and maintained by the Java community, ensuring ongoing support and improvements.
Architectural Overview
It will be helpful to have a high-level architectural overview before discussing the details of the Java Collection Framework.
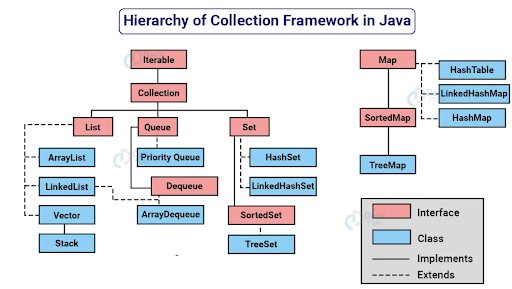
N.B. Of course, there are other classes and interfaces, but we ignored them to keep the class diagram as simple as possible.
As you can see, Collection is a child interface of Iterable. Iterable is the root interface, and it’s directly under java.lang; no classes or interfaces in between. As you can guess by intuition, all the interfaces and classes under the Collection interface, including itself, should form the collection framework. You are almost right with everything except one thing: Map. Though Map is not under the Collection interface, it’s still a part of the framework.
Consider why there are so many interfaces in Java’s collection framework and why it didn’t directly implement the Collection interface.
The Interface Segregation Principle (ISP) suggests that clients should not be forced to depend on interfaces they don’t use. Instead, interfaces should be tailored to meet specific needs.
Java’s collection framework follows this principle by using multiple interfaces (e.g., List, Set, Queue, Deque), each defining a specific set of operations and behaviors. This design ensures that classes only need to implement methods relevant to their type of collection.
If we sum up the above diagram, we see some core interfaces and their implementation classes. Java Collection also provides a set of powerful algorithms to manipulate the collection data. The following sections will discuss these interfaces, classes, and algorithms.
Interfaces And Their Implementation Classes
The foundation of the Java Collection Framework (JCF) is built on a set of core interfaces, each serving a distinct purpose in the organization, storage, and manipulation of data:
Collection
The root of the collection hierarchy represents a group of objects (elements). Collections can allow duplicates to be ordered (e.g., ArrayList, LinkedList) or unordered (e.g., Bags or multisets). The JDK does not provide direct implementations but offers subinterfaces like Set and List. The interface facilitates passing and manipulating collections generically.
List
- An ordered collection (sequence)
- Allows duplicate elements.
- Key methods include–
get(int index)
set(int index, E element)
add(int index, E element)
remove(int index)
Use Case
This is ideal for scenarios where data ordering matters, such as maintaining an insertion order or accessing elements by their index positions.
Implementation Classes
a) ArrayList: Preferred choice for random access operations.
Internal Mechanism
- Dynamic Array: ArrayList uses an internal array to resize itself automatically when added or removed elements are added.
- Initial Capacity: It starts with a default capacity (usually 10) or a specified initial capacity, which can grow when needed.
- Resizing Process: When an ArrayList reaches its capacity, it increases by 50% of the current capacity. A new array is allocated with the increased size, and all existing elements are copied to the new array. The internal reference is updated to point to the new array, and the size of the ArrayList is adjusted accordingly. This resizing process helps optimize performance by reducing the frequency of resizing operations.
- Efficient Access: Accessing elements by index is O(1) due to direct array access.
- Adding/Removing Elements: Adding is O(1) (amortized) when there’s space, but O(n) when resizing; removing an element is O(n) due to shifting elements.
- Memory Management: Maintains the current size and capacity, with memory overhead (internal array) for the object itself.
N.B. Amortized time is the average time for an operation across a series of operations rather than the time for just one operation.
b) LinkedList: Preferred for frequent insertions and deletions.
Internal Mechanism
- Node Structure: Each LinkedList node contains data, a reference to the next node, and a reference to the previous node, forming a doubly linked structure.
- Dynamic Size: A linked list can grow and shrink dynamically as elements are added or removed without needing to be resized like an array.
- Efficient Operations: Adding or removing elements at the head or tail is O(1), while operations at specific indices and accessing elements by index are O(n) due to traversal.
- Memory Usage: Each node requires extra memory for two pointers (next and previous), making LinkedList more memory-intensive than ArrayList.
- Iterators: It provides iterators for traversing the list in both forward and backward directions, taking advantage of its doubly linked structure. Below code is about iterating LinkedList in the forward and backward directions.
// Iterate forward using an iterator
ListIterator<String> forwardIterator = linkedList.listIterator();
while (forwardIterator.hasNext()) {
System.out.println(forwardIterator.next());
}
// Iterate backward using the same iterator
while (forwardIterator.hasPrevious()) {
System.out.println(forwardIterator.previous());
}
c) Vector: Same as ArrayList, except it ensures thread safety, etc.
Internal Mechanism
- Its internal mechanism is almost the same as that of ArrayList.
- ArrayList is generally preferred for most applications due to its better performance and flexibility, while Vector is used in scenarios where thread safety is a priority. However, in modern Java development, ArrayList is more commonly used, and Vector is often replaced by alternatives like CopyOnWriteArrayList when synchronization is needed.
Use Cases
Suitable for legacy code or applications where thread safety is necessary without requiring external synchronization.
d) Stack: provides a simple and effective way to manage data in a LIFO order, leveraging the capabilities of the underlying Vector class while maintaining thread safety. However, alternatives like Deque can be more efficient for non-threaded applications.
Internal Mechanism
- Underlying Structure: The Stack class is built on top of the Vector class, utilizing a dynamically resizable array to store its elements.
- Core Operations: Supports basic stack operations such as push (add), pop (remove), peek (retrieve top element), empty (check if the stack is empty), and search (find element position).
- Time Complexity: The average time complexity for push, pop, and peek is O(1), while resizing the internal array may lead to ]occasional O(n) complexity.
- Thread Safety: The Stack class is synchronized, making it safe for use in multi-threaded environments but potentially less performant in single-threaded contexts.
Use Cases
Commonly used for managing function calls (call stack), expression evaluation, and backtracking algorithms due to their LIFO behavior.
Conclusion
This concludes the first part of the Java Collection Framework. Here, we have given an overview of the Framework, discussed its architecture, and seen some of the implementation classes of the List interface and their internal mechanisms and use cases.
In the next part, we will discuss the other sub-interfaces of the Collection interface, their implementation classes, and how they work internally.