Map is a part of the Java Collection Framework. However, it differs slightly from other collections in the framework because it does not implement the Collection interface directly. Instead, Map is a standalone interface designed for key-value pairs, and it operates differently from the other Collection types(List, Set, Queue) that store individual elements.
In Java, HashMap is a widely used implementation of Map interface within the Java Collection Framework which is by default not synchronized(not thread-safe). It is a hash table-based implementation of the Map interface. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the supplied key is hashed, and the resulting hash indicates where the corresponding value is stored. In this article, we will explore the internals of HashMap.
Internal Structure of a HashMap
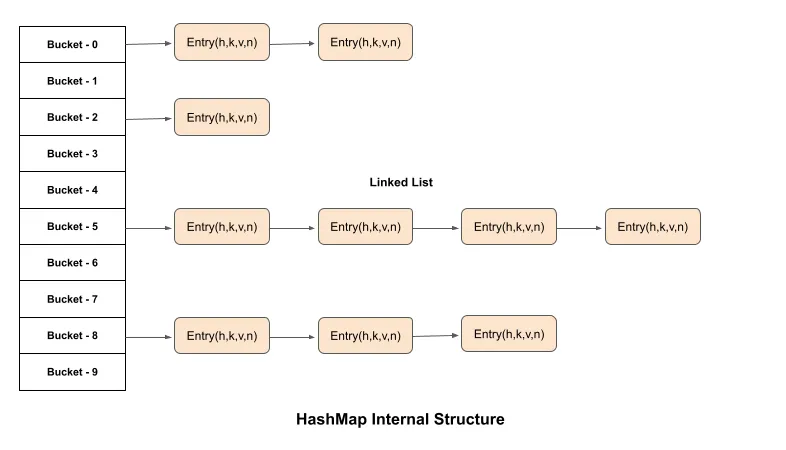
Internally, a HashMap uses an array of buckets or bins. Each bucket is a linked list of type Node, which represents the key-value pair of the HashMap. The Node type is given below:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
The Node class has the following fields:
hash: Refers to thehashCodeof the key.key: Refers to the key of the key-value pair.value: Refers to the value associated with the key.next: This attribute acts as a reference to the next node. It holds the pointer to the next key-value pair and stores the key-value pairs as a linked list.
Hashmap initially takes a fixed no of buckets or bins of key-value pairs of linked list. When key-value pairs in HashMap exceed a certain threshold, determined by the load factor, all key-value pairs would be resized and rehashed. This process is called rehashing or resizing.
The purpose of resizing is to prevent excessive collisions reducing load factor below a certain threshold, which can lead to degraded performance. By increasing the capacity(number of buckets) of the hashmap and redistributing the key-value pairs, the load factor is reduced, and the HashMap can maintain its efficiency.
Few Constant Variables in Map Interface
Before going into further, understanding the following terminologies will be helpful to understand about Java HashMap.
1. Initial and Max capacity: The default initial capacity is 16 which is an initial number of buckets in HashMap. It must be a power of 2. And The maximum capacity it 2³⁰(1 billion entries).
DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16
static final int MAXIMUM_CAPACITY = 1 << 30;
2. Load Factor: As you keep adding elements, the key value of pairs increases in buckets. When the number of elements exceeds a certain threshold, determined by the load factor, the HashMap resizes its internal storage to maintain efficiency. The default load factor is 0.75, which means after a full 75% memory, HashMap will resize with a capacity double. For example, if the current size of HashMap is 16 then the resizing will happen when (16 * 75%) = 12 buckets are full.
static final float DEFAULT_LOAD_FACTOR = 0.75f;
3. Treeify Threshold: When a bucket(an individual bin in the array backing the hashmap) has 8 or more nodes, it switches from a linked list to a tree structure to reduce lookup time from O(n) to O(log n). This threshold improves performance in cases with many collisions.
static final int TREEIFY_THRESHOLD = 8;
4. Untreefiy threshold: During a resize operation, if a bin’s number of nodes falls below 6, it converts the tree back into a linked list. This threshold prevents the structure from maintaining unnecessary tree structures when they’re no longer needed.
static final int UNTREEIFY_THRESHOLD = 6;
5. Minimum treefiy capacity: The minimum capacity of buckets in HashMap must be at least 64 for treeify to occur. If there are too many entries in HashMap but less than 64 buckets, it resizes the entire hashmap rather than converting a bin to a tree from a linked list. This strategy keeps resizing separate from Treeify, improving performance consistency. Below field determines when to treeify of bin or resize of HashMap size.
static final int MIN_TREEIFY_CAPACITY = 64;
Linked list to Balanced trees
Starting with Java 8, if the number of entries in a single bucket of HashMap exceeds a certain threshold (TREEIFY_THRESHOLD, set to 8 by default), the structure of that bucket changes from a linked list to a Red-Black Tree. This optimization helps to speed up search operations in that bucket from O(n) with a linked list to O(logn) using the tree.
During rehashing, this transformation occurs for any bucket with more than 8 entries, ensuring more efficient retrieval as the map grows. However, when the number of entries in a tree bucket drops below a different threshold (UNTREEIFY_THRESHOLD, set to 6), it reverts back to a linked list. This conversion back to a linked list saves memory, as TreeNodes consume more space than basic Map.Entry nodes. By balancing between linked lists and trees based on the number of entries, HashMap achieves both memory efficiency and performance.
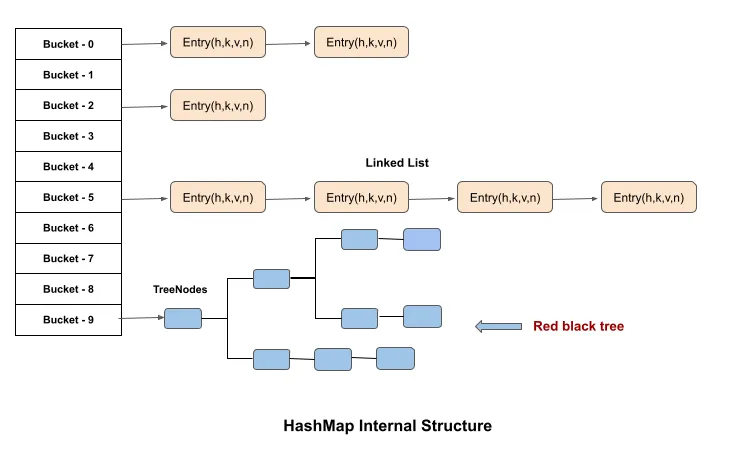
NOTES: In the above image, the tree is not like a balance tree, but imagine it’s a Balance tree.
There are several balance trees such as AVL trees, Red-black trees, Splay trees, etc. Then what is The Red-Black tree? The red-Black tree is a self-balancing binary search tree. The red-black tree makes sure that the length/depth of the binary search trees is always log(n) in spite of new additions or removal of nodes.
The primary benefit of using a Red-Black tree in cases where multiple entries fall into the same bucket is that it optimizes search operations. In Java 7, if entries are stored in a linked list, searching through them takes O(n) time complexity. However, Java 8 introduced a Red-Black tree structure for these cases, reducing search time to O(log(n)) by organizing the entries as a balanced tree instead of a linear list.
Drawbacks: The tree takes more space than the linked list. By Inheritance, a bucket can contain both Node(Entry object) and TreeNode(Red-black tree).
Time Complexity
The basic operations of a HashMap, such as put, get, and remove, generally offer constant time performance of O(1), assuming that the keys are uniformly distributed. In cases where there is poor key distribution and many collisions occur, these operations might degrade to a linear time complexity of O(n).
Under treeification, where long chains of collisions are converted into balanced trees, lookup operations can improve to a more efficient logarithmic time complexity of O(log n).
Thanks for reading. See you! 👋