Introduction
As applications scale and tenant counts grow from dozens to thousands (or even millions), a well-architected multi-tenant system must evolve from “just working” to being operationally scalable, globally available, and cost-efficient. In Part 1, we explored foundational multi-tenant database patterns. Now, in Part 2, we dive into three powerful technologies that enable resilient, performant, and scalable multi-tenant systems: Google Cloud Spanner, Amazon Aurora, and Citus.
The Challenge: Scaling Multi-Tenant Systems
Multi-tenancy amplifies traditional database challenges. You must:
- Isolate tenant data securely at scale
- Maintain performance despite variable and spiky workloads
- Evolve schemas across tenants without downtime
- Ensure availability across regions or zones
- Control costs while still offering SLAs
To address these challenges, let’s focus on three database technologies built for scale.
1. Google Cloud Spanner
Google Cloud Spanner is a fully managed, globally distributed SQL database that combines the benefits of traditional relational databases with the scalability of NoSQL systems.
Key Features
- Global distribution with strong consistency (true horizontal scaling with ACID semantics)
- Automatic sharding (based on primary key ranges)
- High availability with 99.999% SLA
- Support for SQL and secondary indexes
- Interleaved tables to optimize hierarchical queries and co-locate related data
How It Scales
- Data is partitioned into splits, each managed by a node; splits are automatically rebalanced to ensure optimal load distribution
- Spanner uses a distributed Paxos consensus protocol to achieve synchronous replication across nodes and regions
- Every transaction is assigned a globally synchronized timestamp using TrueTime, enabling global consistency without sacrificing performance
- Writes are strongly consistent across regions; reads can be either strongly or eventually consistent based on query semantics
UUID Generation and Performance
- Spanner recommends using sequential UUIDs or composite keys that avoid hotspotting (e.g., tenant_id + timestamp)
- Avoid randomly generated UUIDs as primary keys in high-write tables, as they lead to write amplification due to uneven splits
Multi-Tenancy Best Practices
- Shared table model: Use tenant_id as part of the composite primary key to co-locate tenant data
- Use interleaved tables for tenant-scoped child entities to reduce I/O and join costs
CREATE TABLE tenants (
tenant_id STRING NOT NULL,
name STRING,
) PRIMARY KEY (tenant_id);
CREATE TABLE orders (
tenant_id STRING NOT NULL,
order_id STRING NOT NULL,
order_date TIMESTAMP,
total_amount FLOAT64,
) PRIMARY KEY (tenant_id, order_id),
INTERLEAVE IN PARENT tenants ON DELETE CASCADE;
Ideal Use Cases
- SaaS platforms operating globally
- Applications with strict SLAs and global user bases
- Multi-tenant applications needing strong consistency and automatic horizontal scale
2. Amazon Aurora (MySQL/PostgreSQL Compatible)
Amazon Aurora is a cloud-native relational database built for high performance and availability. It is compatible with MySQL and PostgreSQL, making it an easy lift for most applications.
Key Features
- Storage auto-scales up to 128 TiB
- 15+ read replicas for scaling read-heavy workloads
- Aurora Serverless mode supports variable workloads
- Aurora Limitless (PostgreSQL) enables massive write throughput
- Fast recovery and backup: Log-based backups with point-in-time restore
How It Scales
- Aurora separates compute and storage layers; storage is shared across compute nodes and automatically scales in 10 GiB increments
- It uses a quorum-based replication strategy (4 out of 6 quorum model) for distributed writes across three availability zones
- Aurora Serverless v2 allows fine-grained autoscaling down to fractions of a vCPU
- Read replicas are used for horizontal read scalability and failover support
UUIDs and Indexing Considerations
- MySQL users should be cautious with random UUIDs as primary keys; they increase index fragmentation. Prefer time-based UUIDs or numeric IDs
- PostgreSQL Aurora can benefit from sequential identifiers and partial indexes to speed up tenant-specific queries
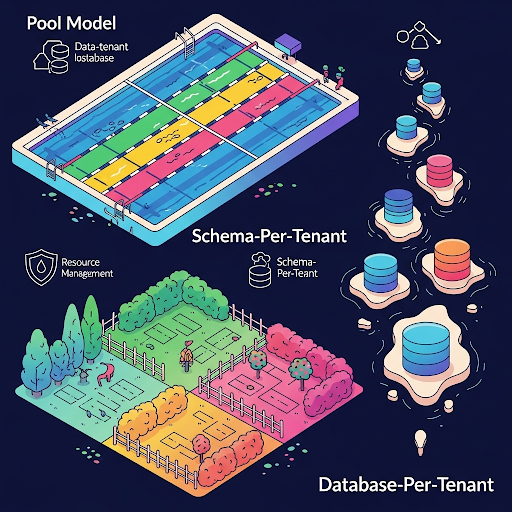
Multi-Tenancy Best Practices
- Schema-per-tenant for better modularity, easy permissioning, and simplified backup/restore
- Shared schema with tenant_id column for large-scale shared tenancy
- Use query caching and read replicas for bursty workloads
-- Pool model
SELECT * FROM orders WHERE tenant_id = 'abc-123';
-- Schema-per-tenant
CREATE SCHEMA tenant_abc;
CREATE TABLE tenant_abc.orders (...);
Ideal Use Cases
- SaaS platforms with varying read/write workloads
- Applications needing compatibility with MySQL or PostgreSQL
- Cost-sensitive environments with predictable but bursty usage patterns
3. Citus (PostgreSQL Extension)
Citus transforms PostgreSQL into a distributed, horizontally scalable system by sharding tables and distributing queries across nodes.
Key Features
- Distributed SQL with PostgreSQL API
- Automatic sharding and query parallelism
- Supports columnar storage (for mixed OLAP/OLTP workloads)
- Tenant-aware sharding for multi-tenant applications
How It Scales
- Citus shards tables based on a distribution key (e.g., tenant_id)
- Each tenant’s data lives in one or more shards
- Citus routes queries to the relevant shards only, minimizing I/O
- Parallel processing across shards boosts performance
- Can colocate multiple tenant tables in the same shard for improved joins
Multi-Tenancy Best Practices
- Use tenant_id as the distribution column
- Co-locate tenant data using colocated tables (foreign key relationships must share the distribution key)
- Apply row security policies or role-based access control
-- Enable distributed table
SELECT create_distributed_table('orders', 'tenant_id');
-- Queries are automatically routed
SELECT * FROM orders WHERE tenant_id = 'xyz';
Ideal Use Cases
- PostgreSQL-based SaaS products needing scale-out
- Multi-tenant analytics and reporting platforms
- Apps requiring sharding without giving up PostgreSQL features
Key Takeaways
- Google Cloud Spanner is best for global, high-availability, high-throughput systems with complex multi-tenant isolation needs. It offers built-in sharding, interleaved tables, strong consistency, and global replication.
- Amazon Aurora offers an excellent balance of performance, compatibility, and cost-efficiency, with serverless scaling, read replicas, and per-AZ resilience. Ideal for teams familiar with MySQL/PostgreSQL.
- Citus enables PostgreSQL teams to scale horizontally without migrating to new engines. It’s ideal for SaaS platforms that want to retain full PostgreSQL functionality while scaling out.
Each of these tools supports tenant-aware design and horizontal scale—but their internal architectures, cost models, and operational practices differ. Choosing the right one depends on your tech stack, budget, growth plans, and compliance requirements.
In a future post, we will explore hybrid patterns for multi-tenant design combining them with noSQL databases, primarily DynamoDB, or Cassandra.