Browsers are complex software applications that enable users to access, retrieve, and interact with information on the WWW. They are considered single-thread applications. It is the developers’ responsibility to improve browser performance so we have to understand in depth the different components of browsers and how they work.
Delivering a fast web experience is our daily life job. Browsers need to do a lot of work, and most of the work is hidden from us. But how do browsers consume HTML, CSS, and JavaScript to render pixels on screen? What happens when a URL is entered? We will discuss all of the stuff in this blog.
Browser Components
First, we have to understand the browser’s components. The diagram below shows different parts of the browser components.
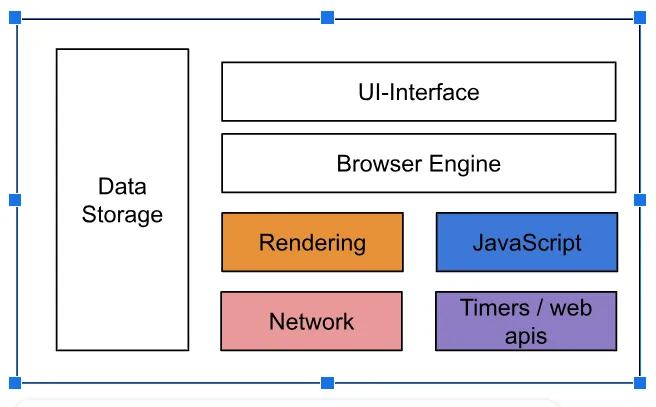
A browser generally consists of:
- User Interface (UI): Buttons, address bar, tabs, etc.
- Browser Engine: Mediates between the UI and rendering engine.
- Rendering Engine: The renderer engines are written in C++, Rust, etc. Google Chrome Renderer Engine is written in C++. It converts HTML elements into node lists and renders web content (HTML, CSS) on the screen.
- JavaScript Engine: Executes JavaScript code.
- Networking Layer: Handles network requests.
- Data Storage: Manages cookies, local storage, session storage, and cache.
Browser’s visual Job for its User
The browser’s primary job for users is to:
- Display Data: Render the visual content for users.
- Enable Interactivity: Facilitate interactions with the rendered data.
Below, we will discuss how browsers display a website and facilitate interaction with data.
Navigation
Navigation is the first step in loading a web page. It happens when a user enters a URL in the browser tab, and clicks a link/button or any other way. One of the main goals of web performance is to reduce the time for navigation to complete.
DNS Lookup
After the navigation, the browsers sent a request for DNS lookup which means to find an IP address against the domain name. After the initial response of the IP address, the browser caches it for further subsequent requests with the same domain.
Ever wondered what happens when someone enters a simple URL like google.com into the browser? When you hit Enter on your browser with such a URL, the following things happen:
- Browser Cache: The browser first looks through its local cache to find the IP address for that domain. If it doesn’t find anything, it checks the service worker cache next.
- OS Search: If the address isn’t in those caches, the browser looks through the OS cache for any related data.
- ISP Cache: Still nothing? Now it’s time for ISP (Internet Service Provider), which keeps a cache of frequently requested domains to save time.
- DNS Lookup: If the IP address is still not found, the request reaches the DNS(Domain Name System), which works in four phases to resolve the domain.
- Root Level: Starting at the highest level, it checks the root servers.
- Top Level: The browser then checks for the TLD(.com, .net, .gov, etc)
- Second Level: Next, it looks up the domain itself(e.g, google of google.com)
- Third Level: Finally, the browser searches for subdomains like www.google.com.
Once DNS finds the IP, it sends it to your ISP, which passes it back to the device. At this point, the browser sends a request for a handshake with the server(e.g., google.com), which is acknowledged by the server.
TCP(Transmission Control Protocol) Connection
After the DNS Lookup, browsers connect with a server through TCP handshaking. TCP handshaking is nothing but establishing a reliable connection between two devices over a network before data transmission. The TCP handshaking process involves three key steps:
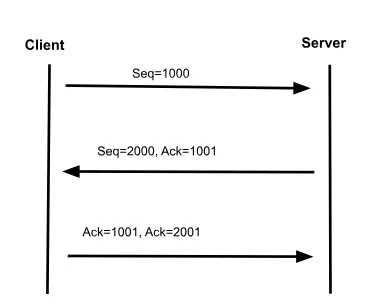
1. SYN(Synchronization): The client sends a SYN packet to the server to initiate a connection. This packet includes a unique sequential number.
Client → Server: SYN, Seq=1000
2. SYN-ACK(Synchronize-Acknowledgement): The server responds with a SYN-ACK packet to agree to the connection. The packet has the server’s own randomly generated sequence number. And an acknowledgement number which is the client’s sequence number incremented by 1.
Server → Client: SYN, Seq=2000; ACK, Seq=1001
3. ACK(Acknowledgement): The client receives SYN-ACK packet and responds with an ACK packet having server sequence number incremented by 1.
Client → Server: ACK, Seq=1001; ACK, Seq=2001
At this point, the connection is fully established, and the client and server can begin exchanging data. Still, data exchange has not happened. After connecting via TCP, the browser wants to secure communication with the server. Then it asked about any SSL/TLS certificate within the server. If no SSL/TLS certificate is found, then the data is exchanged without encryption.
What is SSL/TLS?
SSL (Secure Sockets Layer) and TLS (Transport Layer Security) are cryptographic protocols designed to provide secure communication over a network. TLS is the successor to SSL, with enhanced security and performance features. You can google for a better understanding or I’ll discuss it later in another blog.
How do HTML, and CSS download and construct Object Models?
Now we will see how the browser handles resources. When a browser loads a webpage, it follows a structured series of steps to fetch, parse, and render the content on the screen. Below is a detailed explanation of this process:
1. Fetch phase
Retrieves HTML, CSS and JS, and other resources from the server. The resources are loaded in a binary format(raw bytes) and passed to subsequent phases for processing.
2. Parse Phase
HTML: The process of parsing an HTML file involves:
- Loading Raw Bytes: The HTML file is received in binary format.
- Converting to Character: The binary data is decoded into a sequence of characters using the appropriate encoding.
- Tokenization: The characters are split into meaningful chunks called tokens(e.g.,<div>,<p>).
- Building structure: After tokenization, tokens are converted into objects/nodes, which form a tree-like structure. This structure includes relationships like parent, child, and samplings. Actually, converted into NodeList.
- Creating the DOM: The document Object Model is finally created. The DOM represents the structured layout of the webpage and contains objects of every element in the HTML.
CSS: The process of parsing CSS files is similar to HTML. But it builds CSSOM instead of DOM. DOM and CSSOM are completely independent. Parallelly CSSOM was created besides DOM. They are eventually combined to form the rendering tree. This tree is then used to determine the visual layout of the page.
3. Rendered Tree
It gathers the information of DOM and CSSOM and gives it to the Browser Engine. Browser is a master in math and a lot of mathematical calculation is done. This merged tree is passed to the Browser Engine which performs a complex mathematical calculator to determine how elements should appear on the screen.

4. Layout
Calculate the exact position and size of every element on the page in the Render Tree. The process involves applying various layout algorithms like the box model, flexbox, and grid layout. Then we got a rendering tree. And at that moment the painting started.
5. Painting
The browser paints the element onto the screen, pixel by pixel.
How does JavaScript download and execute?
When the browser encounters a <script> tag in the HTML, it pauses further HTML parsing to download, parse, and execute the JavaScript unless async or defer is used.
Blocking behavior of JavaScript
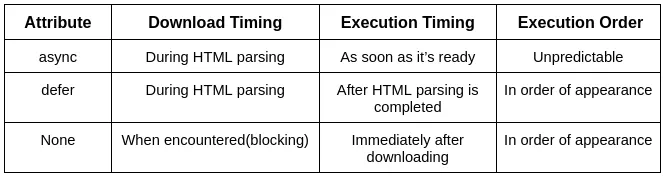
By default, <script> tags block HTML parsing. Without async or defer, the browser:
- Stops parsing HTML.
- Downloads and executes the script.
- Resumes parsing the HTML.
This blocking behavior can delay the page load, especially if the script is large or hosted on a slow server.
Async Attribute
The script is downloaded asynchronously while the HTML is being parsed. Scripts are executed as soon as they’re ready and the execution order is unpredictable(depends on which script loads first).
<script src="script.js" async></script>
Defer attribute
The script is downloaded asynchronously while the HTML is being parsed. The script is executed after the HTML parsing is completed, in the order they appear. Ensures the DOM is fully constructed before the script runs.
<script src="script.js" defer></script>
Comparison between sync, defer, and None
Best practices
- Use defer for scripts that depend on the DOM (e.g., UI scripts).
- Use async for independent scripts (e.g., analytics).
- Place blocking scripts at the end of the <body> tag if async or defer are not used.
- Minimize JavaScript and use bundling techniques for better performance.
Resources
- https://web.dev/articles/critical-rendering-path
- https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work
Thanks for reading. See you! 👋