Redis is designed for exceptional speed. A single Redis server can handle 100,000 to over 1,000,000 queries per second (QPS), depending on hardware and command complexity. In comparison, traditional SQL databases such as PostgreSQL or MySQL typically support 10,000 to 100,000 QPS, depending on query complexity, indexing, and hardware.
So, what is the secret behind this blazing speed? How does Redis achieve it, and what architectural principles make it possible? Let’s dive deep into the underlying mechanisms that make Redis exceptionally fast.
In-Memory Architecture
To store data traditionally, we use different types of storage, and every storage type has a different I/O operation speed. We mostly use RAM to run applications for its faster I/O operation capabilities. RAM can read or write 1 byte of data directly, but disk storage usually reads or writes data in larger blocks (typically 4KB). So, to perform a 1-byte I/O operation, disk storage still needs to read or write a larger block. Because of this, RAM helps minimize CPU load during I/O operations.
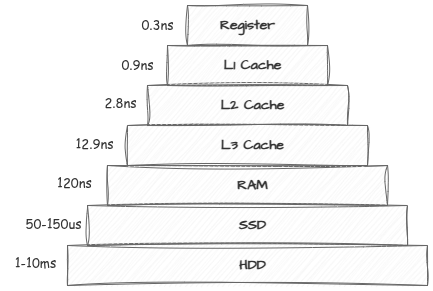
Redis operates primarily in memory (RAM) rather than on disk. This design choice eliminates the performance bottleneck of disk I/O operations. Also, since data is stored in RAM, CPU cache utilization is optimized for frequently accessed data, making it more efficient.
But what about data persistence? We know that if the system restarts, RAM can’t retain data. Redis offers persistence options (RDB snapshots and Append-Only File logs) to solve this. These operate asynchronously, ensuring that the primary data operations stay memory-bound and lightning-fast.
Single-Threaded Event Loop
Redis handles all client requests using a single thread. At first, this might sound counterintuitive, but it’s a smart design choice.
Imagine you want to build a view counter for this blog. Suddenly, the blog goes viral, and millions of users start reading it simultaneously. To ensure an accurate and real-time view count, if you use a typical SQL database, each user request would require acquiring a lock on the view counter before updating it. This synchronization introduces significant overhead when using multiple threads. For millions of users, managing locks becomes a massive performance bottleneck.
Instead of relying on multiple threads—which introduces complexity from context switching, locking, and synchronization—you can simply use a single-threaded solution. In Redis, when a user arrives, an event to increment the view counter is added to a queue. These events are then processed in a loop, one at a time, in a consistent and predictable order. This design allows a single thread to efficiently handle millions of client requests without the overhead of thread contention or lock management.
However, Redis does use multiple threads sometimes—for example, for input/output (I/O) tasks like reading or writing data to the network. While the main processing stays single-threaded to keep things simple and consistent, Redis runs these I/O-heavy operations in the background using multiple threads. This helps reduce waiting time and makes Redis faster and more responsive overall.
Optimized Data Structures
Most of us start learning Redis to use it for caching, but Redis is much more than that. It provides a rich set of specialized data structures that allow you to build almost anything on top of it. For example, you can use Redis as a queue by leveraging its list data structure, suitable for background job processing, task queues, or message passing between services.
All of these data structures are implemented in ANSI C, optimized for high performance, low memory overhead, and fine-grained control.
- Strings: Implemented as binary-safe C strings, capable of storing any kind of data, from simple text to serialized objects. They support constant-time O(1) access and update operations, making them ideal for counters, tokens, or cached values.
- Lists: Internally implemented as a combination of linked lists and compressed arrays. It offers fast push/pop operations from both ends with O(1) time complexity, making them perfect for queues, logs, or job buffers.
- Sets: Implemented using hash tables, designed to store unique items. Supporting O(1) time complexity for membership checks, insertions, and deletions, making them suitable for tagging, deduplication, and presence tracking.
- Sorted Sets: Implemented using a combination of hash tables and skip lists, enabling fast range queries and score updates in O(log N), used in leaderboards, priority queues, and time-series ranking.
- Hashes: Implemented as key-value hash maps with separate chaining, optimized for small data. Access to individual fields is constant time O(1), making them ideal for structured data like user sessions or object storage.
Smart Memory Management
We know that disk storage is much cheaper than in-memory storage, and in real-world scenarios, no one has unlimited RAM. That’s why smart memory management is a must-have optimization in Redis.
Let’s discuss some optimization techniques:
- Compression of small integers: Small integers are stored using efficient internal encoding to save space.
- Shared objects: Frequently used values (like small integers or common strings) are shared across clients to reduce memory usage.
- Memory reclamation policies: Redis supports configurable memory eviction strategies like LRU to automatically free up space when memory limits are reached.
These optimizations help Redis store more data in RAM and maintain high performance under memory constraints.
Conclusion
Redis is extremely fast because of smart design choices, efficient code, and constant optimization. Its in-memory architecture is the base of its speed, but what makes Redis stand out is the attention to detail in every part of the system. From the single-threaded event loop to the way its data structures and memory are optimized, everything is built for performance.
By understanding how Redis is designed under the hood, we can learn important lessons for building other high-performance systems too.