In the world of digital data, Bloom filters are highly significant. They can quickly find a username in massive databases using very little memory. Burton H. Bloom created these filters, which completely changed how we search for things, saving space and cutting down on incorrect results.
What Is A Bloom Filter?
A Bloom filter is helpful for quickly checking whether something belongs to a particular group. It uses a small amount of space and makes intelligent guesses. It has many uses in computer networks, databases, and systems across different locations. Its flexibility means that we can use the filter in many different ways, and it has the potential to solve many other problems.
Remember this: A Bloom filter comprises a bit array of length m and k independent hash functions, where m is the size of the array and k is the number of hash functions. The filter initializes the array with all bits set to 0.
We can use a simple bloom filter with Redis, Memcached, or Amazon DynamoDB to efficiently handle large datasets. If we choose Redis, a widely used in-memory data store, we can install the RedisBloom module on our server. This module provides built-in support for Bloom filters in Redis, which makes the implementation and usage process easier. Although DynamoDB and Memcached do not natively support bloom filters like Redis does with the RedisBloom module, we can still create a bloom filter using DynamoDB and Memcached by implementing and storing the bloom filter data structure.
How Does it Work?
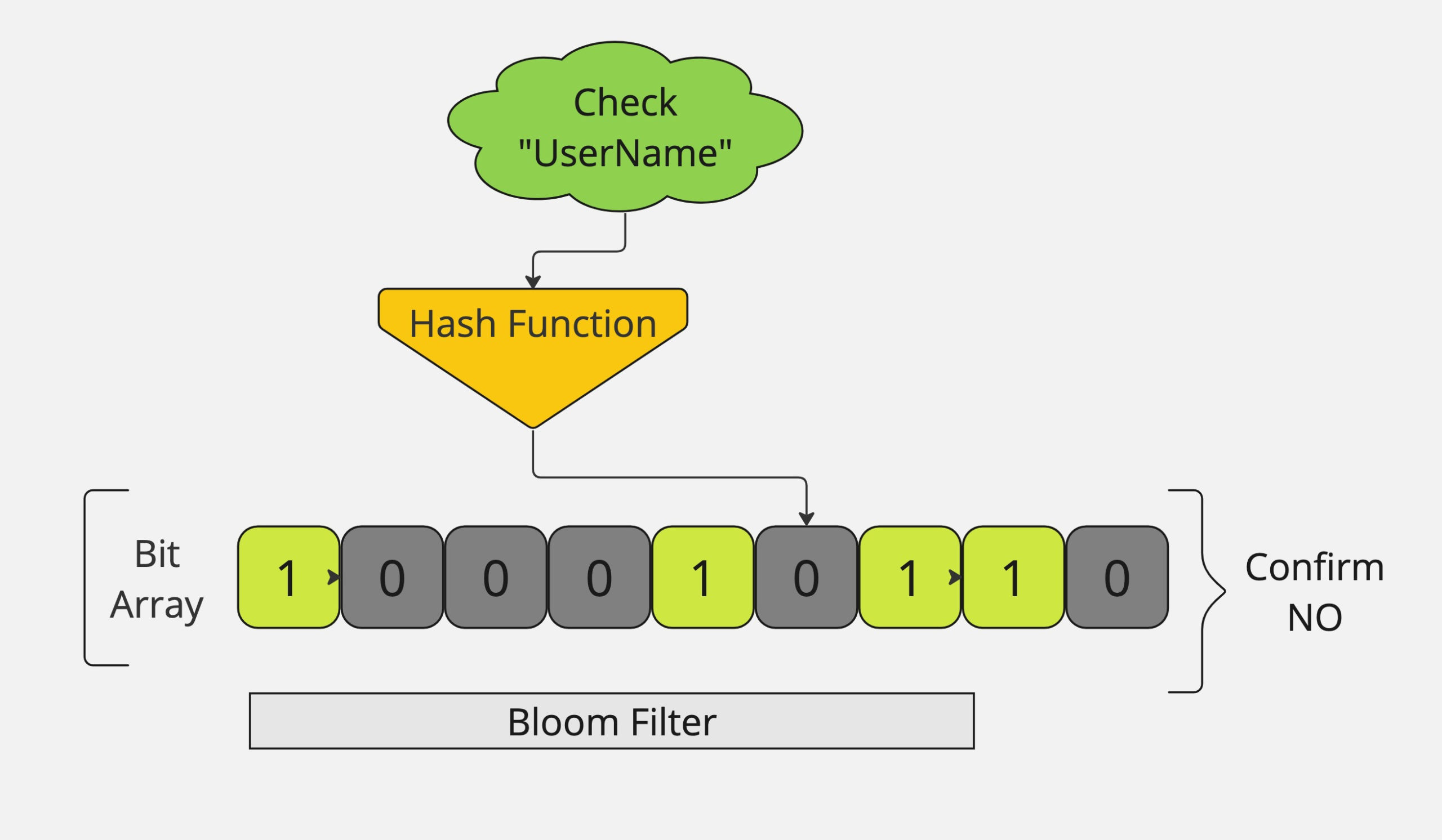
When we add something to the Bloom filter, we run a series of tests called hash functions on it. Each test puts the item into one of the bits in a list of bits, making that bit a 1.
We use the same tests to check if the item is in the set. The filter can tell us the item might be in the set by making certain bits in the list 1. However, the item is not in the set if any bits are 0.
Bloom filters can mistakenly suggest that an item is in the set when it’s not, known as false positives. While this is a downside, it’s a trade-off for their efficiency. Understanding this helps us make informed decisions about using Bloom filters for data management.
Rest assured, Bloom filters avoid making the opposite mistake. A significant feature of Bloom filters is their trustworthiness. If a filter confidently states that an item is not in the set, we can rely on it.
Hash Function Explore
To better understand Bloom filters, let’s examine how hash functions, bit manipulation, and diagrams help them work.
Bloom filters rely on hash functions, which turn an input into a fixed-size output called a hash value. This hash value is like a unique ID for an item in the Bloom filter. The functions place items into spots in the bit array. Adding something to a Bloom filter calculates its hash using multiple hash functions or just one. Each hash function decides which spots in the bit array to mark as 1. This way, Bloom filters can quickly check if something is in the set, although there’s a chance of some mistakes.
Example:
The diagram to check considers a simplified example of a Bloom filter with 8 bits and three hash functions. Let’s insert the element “username” into the Bloom filter:
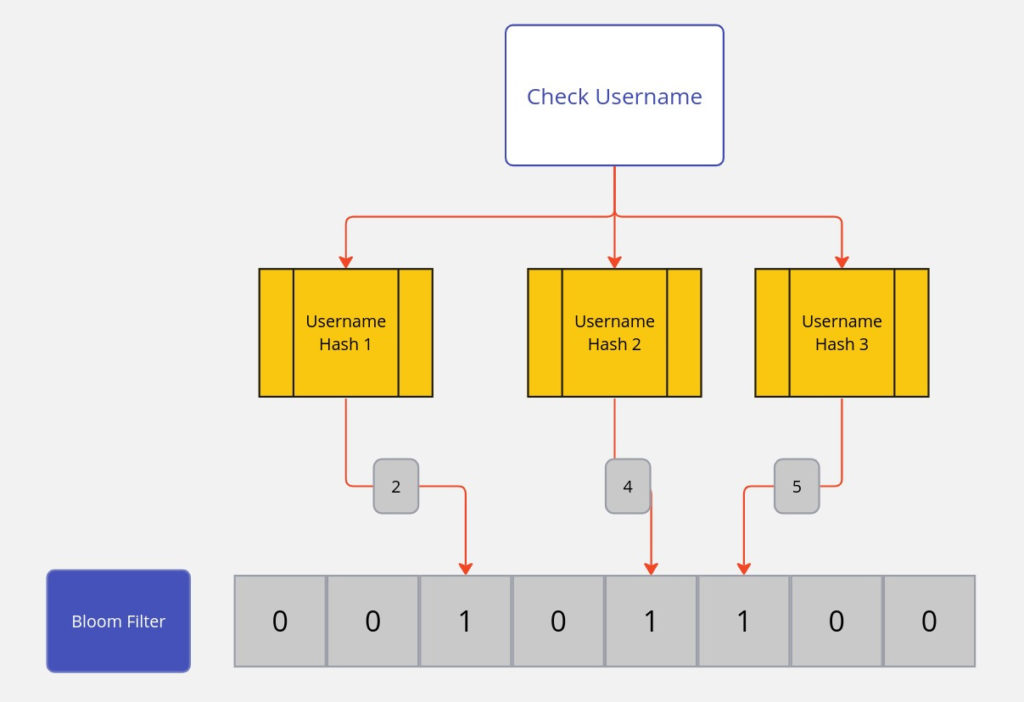
Hash Function 1: Hash(“username”) = 3 (mod 8) = 2
Hash Function 2: Hash(“username”) = 7 (mod 8) = 4
Hash Function 3: Hash(“username”) = 5 (mod 8) = 5
Remember, Bloom filters work best with multiple hash functions to reduce false positives by spreading elements out more effectively. Using only one hash function can decrease the workload but increase the likelihood of false positives. If the Bloom filter sets all bits of an array to 1, consider increasing the filter size or adjusting the hash functions.
Bloom filters have limitations. We cannot delete elements because they don’t track which elements set bits. To delete an element, we must rebuild the Bloofilteril, reset all bits to 0, and reinsert the remaining components.
Bloom filters have a wide range of applications in different situations:
Caching: Bloom filters are commonly used in web browsers and network devices to check if a URL is rapidly associated with malicious content, or if a particular resource is already cached.
Spell Checkers: Bloom filters efficiently determine if a word is present in a dictionary. This functionality resembles searching in an index, enabling quick checks for the existence of words.
Username: Bloom filters can quickly tell you if a username is available, making it easy to check if someone else has already taken it.
Understanding how Bloom filters use hashing and bit manipulation to determine set membership is essential. Knowing the principles behind hashing, bit manipulation, and parameter calculation is vital for effectively implementing and using Bloom filters in various applications.
Reference
https://dl.acm.org/doi/10.1145/362686.362692 [Author Publication]
https://hur.st/bloomfilter/ [Bloom Filter Calculator]
https://www.primevideotech.com/search-and-information-retrieval/how-simple-bloom-filters-helped-prime-video-solve-a-duplicate-problem [Bloom filters helped prime video solve a duplicate problem ]
https://medium.com/@himanshubarak/bloom-filter-the-data-structure-built-for-speed-search-2a9361136d2 [C++ Implementation]